Next level HPC: NeSI user wins access to one of the world’s top supercomputers
“I know I can write to NeSI whenever I need to. They’re incredibly intelligent, incredibly supportive, and the turnaround time on solutions is just wonderful."
Subject:

Dr. Philip Sharp, a senior lecturer in the Department of Mathematics at the University of Auckland, has been using NeSI to study the early evolution of the Solar System.
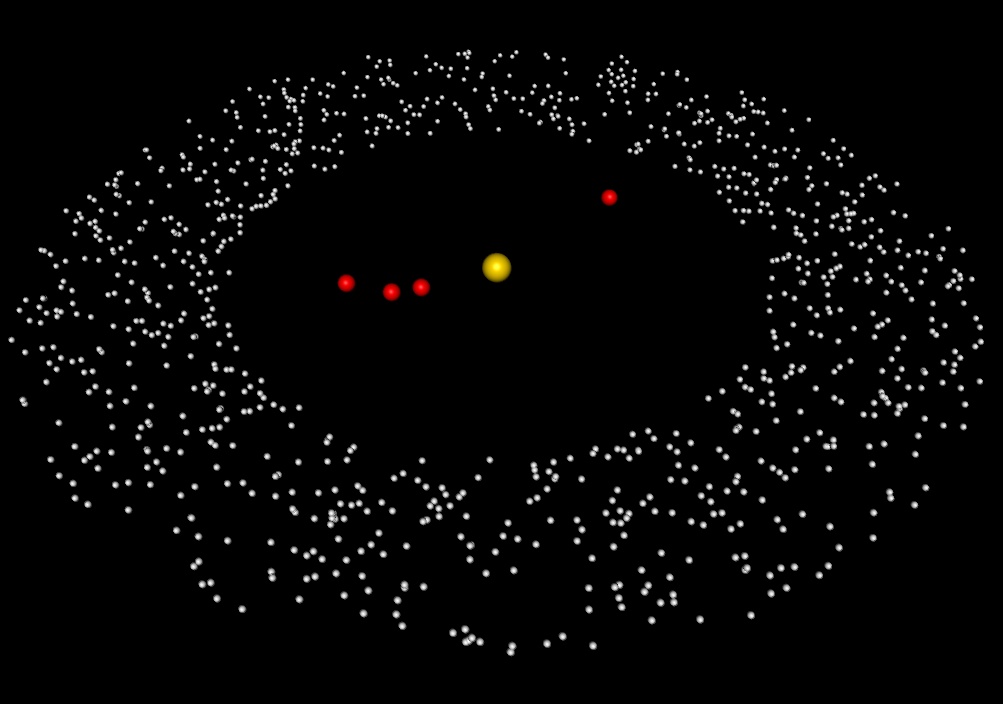
Sharp is collaborating with William Newman, a Professor in Physics & Astronomy at UCLA, to investigate whether the Nice model, the leading model for the Solar System’s evolution, accurately predicts the present day orbits of the giant planets, Jupiter, Saturn, Uranus and Neptune. In addition to the giant planets, the Nice model also includes the Sun and N-5 small bodies called planetesimals (see Figure 1).
As part of his investigation, Sharp uses mathematical methods called N-body simulations. His latest simulation program, running on a single Graphics Processing Unit (GPU), has performed simulations of 20 to 100 million years with N=1024 astronomical bodies. Although this value of N has been used by other research groups, Sharp and Newman are the first to perform accurate simulations with this value. Results of that work were published in the Journal of Computational Science.
"Collisionless N-body simulations over tens of millions of years are an important tool in understanding the early evolution of planetary systems,” says Sharp. “Our method is significantly more accurate than symplectic methods and sufficiently fast.”
So far, results from these simulations show the Nice model is unstable for the number of bodies researchers use with the model. This instability therefore limits its predictive power. To strengthen this argument, Sharp and his colleagues wanted to perform accurate simulations with larger values of N, however they were limited by their existing simulation program because the elapsed time would be too large.
This is where Chris Scott from NeSI’s Computational Science Team stepped in to help. Although Sharp’s simulation program was already well optimised, further gains could be made by modifying the program to run on multiple GPUs at once.
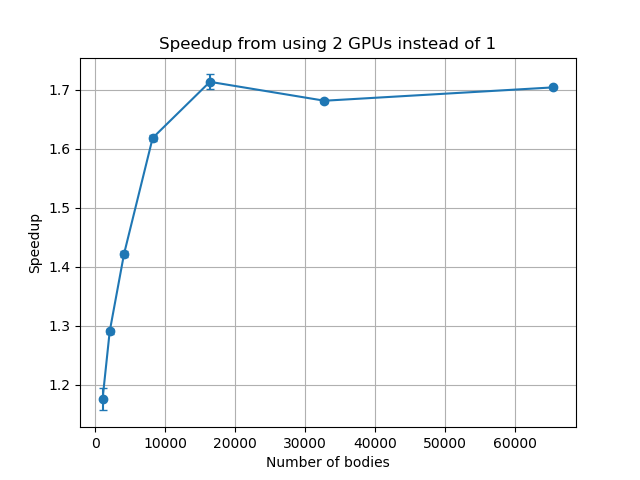
With Scott’s help, the researchers were able to convert their simulation program to make use of all available GPUs within a node from a single CPU core. They applied this to a range of numbers of bodies, from 1,024 to 65,532, and immediately observed a modest improvement in performance when working with the lower numbers of bodies. As they switched to larger numbers of bodies, which are of more interest to Sharp, the gains were even greater, with a 1.7x speedup observed for simulations with 16,384 or more bodies.
Scott then experimented with introducing OpenMP, an Application Programming Interface (API) commonly used for parallel programming, and the combined speedups from using two GPUs and OpenMP were 1.9x for 4,096 bodies, 2.0x for 16,384 bodies, and 1.8x for 32,768 bodies.
“As a result of these changes, the simulation program is now running up to two times faster than previously,” says Scott. “Also, these gains will allow researchers to run simulations of larger systems in a more reasonable time and verify the results obtained from their calculations.”
Tackling these types of research questions relies heavily on access to high performance computing (HPC), says Sharp.
“Put simply, the work would not be possible without HPC,” he says. “We chose NeSI because its HPC resources are the best in the country.”
As they continue their work in this area, the insights uncovered by Sharp and his colleagues will further strengthen the Nice model as a tool for explaining how the Solar System is evolving.
"Our results clearly signpost what to do next - perform simulations with a lot more bodies,” Sharp says. “We expect, as happens with galactic simulations, that increasing the number of bodies will make the Nice model more stable and hence improve its predictive power.”
Getting Technical
Below you’ll find additional, more technical details describing the NeSI Team’s solution to Sharp and Newman’s research challenge. If you need support for your research projects, contact support@nesi.org.nz.
By using pinned memory and asynchronous memory transfers we were able to execute memory transfers and kernel calls concurrently on both GPUs from a single host CPU process.
The speedups obtained by running on two GPUs compared to one are shown in Figure 2. The initial increase is due to the GPUs not being fully utilised at lower numbers of bodies.
The performance improvements achieved by using two GPUs came at no extra cost in terms of core hours, since only a single CPU core is used.
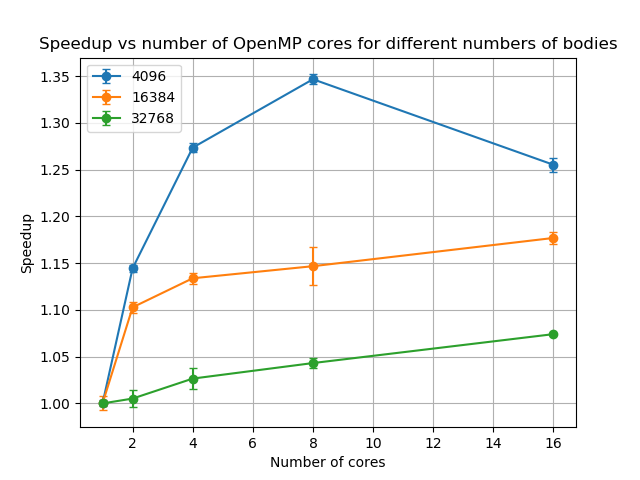
In the current implementation of the simulation code, the integrator runs on the CPU. By converting the loops in the integrator to use OpenMP, we were able to achieve an even greater boost in performance, as shown in Figure 3.
OpenMP had a greater benefit at lower numbers of bodies. For 4,096 bodies, the serial version of the integrator accounted for 21% of run time but this dropped to 9% for 32,768 bodies, showing that the acceleration calculation dominates the run time for higher numbers of bodies.
We also implemented a vectorised OpenMP version of the simulation program for comparison with the GPU versions. We found that at best the OpenMP version was half the speed of the GPU version and performed worse as the number of bodies increased. The pure OpenMP version may perform better on more recent architectures, where the vector width has been doubled.
Further improvements, particularly at lower numbers of bodies, may be possible by moving the integrator onto the GPU, although to ensure accuracy a complex integrator was used and therefore this may not be a trivial change.
In the future, it would be possible to extend this to run across multiple nodes, however this would have the overhead of passing data between the nodes.