

Deep learning in land care research
"We're looking at how we can further automate those processes to make them more efficient so they can be run more frequently, for example to keep up with the rate that satellite imagery is now being produced."

Research background
Ice shelf cavity modelling is key to determining Antarctica's melt rate, which in turn is critical to predicting the rise of sea level as a result of climate change.
Researcher Alena Malyarenko (NIWA, Antarctic Science Platform National Modelling Hub, Antarctic Research Center Victoria University Wellington) is running an ocean model, MITgcm, for the Ross Sea in Antarctica. MITgcm is a static Fortran code, which supports a hybrid MPI and OpenMP parallelism.
The input data are binary and the code compiles and runs successfully using the Cray compiler. A high resolution case (1000x1000x70 cells) uses about 600 cores so any performance improvement can result in significant research productivity improvement.
Project challenges
It takes a couple of weeks to run the hi-res model (30 years of ocean time). The goal is to compile MITgcm optimally on NeSI platforms and find the best configuration (domain decomposition, number of threads, etc.) to minimise wall clock time.
Related to the previous challenge is the need to explore whether tile blanking can bring additional performance benefits. The computation domain includes areas where there is no ocean (e.g. ice or land) and the ocean code MITgcm has an option to blank out these areas at the granularity of MPI subdomains. This would allow for a smaller number of processes to be used, making the code more efficient to run and reducing the turnaround time between simulations.
What was done
NeSI tried different compilation options. Starting with a working executable compiled by NeSI application support team member Wes Harrell, we gradually introduced more aggressive compile options and checked for changes in the results.
Compared pure MPI with hybrid MPI + OpenMP execution. Given that OpenMP threads are lighter weight than MPI processes, there might be an advantage in using a hybrid approach on shared memory platforms such as maui and mahuika.
Devised a strategy for blanking tiles. This is an iterative process whereby one runs MITgcm initially with no blanking. From the print out of the code one can find how many tiles can potentially be blanked. This then requires an adjustment of the domain decomposition. The trick is to find a domain decomposition that yields the number of processes matching the initial domain decomposition minus the number of blanked tiles
Main outcomes
+5% performance by adding “-hipa5 -halias=none -Oaggress -hflex_mp=tolerant” to “-O3 -hfp3” when using the Cray compiler
+2% performance improvement, observed when running MPI 10x8 domain decomposition against MPI+OpenMP 5x4+4threads
The default vectorisation level (-h vector3 -h preferred_vector_width=256) works well
Profiling with ARM MAP revealed that 29% of the execution time is spent performing floating point operations. This is regarded as a high value, indicating that the code is highly optimised
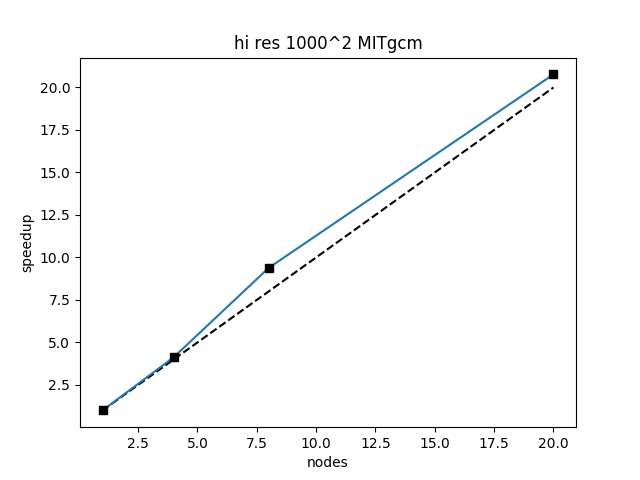
MITgcm is highly scalable with MPI communication taking less than 20% of the execution time. The speedup is slightly superlinear, suggesting the code prefers smaller sub-domains which can lead to fewer memory cache misses
+45% efficiency improvement obtained by blanking 219 tiles out of 625 (35%). This reduced the number of nodes from 8 to 6 with only 2 tiles left unblanked. Alena was able to find another, even better, configuration with blanking applied to all land tiles.
Researcher feedback
"Testing the high-resolution case on Maui can be time-consuming. The eight node configuration does not allow for using the Debug partition, so on a good day I was able to have two attempts at running the model. The number of tests that were conducted in this Consultancy would not be possible to run by me in such a short time period. However, the confidence in my model set up and additional improved efficiency are crucial at the beginning stages of the project. Many thanks to the team for the provided support."
- Dr Alena Malyarenko, Process-Scale Ice Shelf Cavity Modeller, NIWA
Do you have a research project that could benefit from working with NeSI research software engineers or a data engineer? Learn more about what kind of support they can offer and get in touch by emailing support@nesi.org.nz.





