

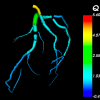
Modelling coronary artery bypass grafts
"With NeSI’s help, the more sophisticated vessel networks were being solved in several hours, whereas on prior estimates they would have taken a few months."
Subject:

Research background
Damien Mather is a Senior Lecturer in the Department of Marketing at the University of Otago. His current research project involves big-marketing-data analysis, focussing on supermarket scan panel data, although potential applications extend to all applied sciences.
Damien is experimenting with improving the quality and practicality of marketing insights generated for businesses from this type of big data. Initially he is focussing on the yogurt category, generating insights for brand, formulation, flavour and price and is using a combination of experimental design algorithms to sample the big data in innovative ways to improve D-efficiency whilst maintaining population representativeness of the sample and then multinomial logit models of availability and cross-availability.
Project challenges
The limiting factor in Damien’s project progress is the experimental design search algorithm's iteration of the log-determinant calculations on each improved design and over each candidate design swapping pair. This calculation is performed many times and is a major bottleneck in terms of performance.
The aim of the NeSI Consultancy project was to optimise Damien’s function for computing the log-determinant, based on the matrix condensation method originally published by Rev. Dodgson. The aim was to take advantage of the available hardware by using OpenACC to utilise GPUs and MPI to run across multiple processes (and multiple GPUs) to achieve the best performance.
What was done
Setting up the PGI compilers on NeSI’s Mahuika platform to work with CUDA and Intel MPI
Added a CMake build system (cross platform, makes it easy to build multiple versions of the same code and automatically detects compiler flags for OpenACC, MPI, etc.)
Benchmarking and profiling the initial implementation to identify optimisation opportunities
Optimise data locality and use non-blocking MPI calls to improve performance
Main outcomes
1.2-2.1x speedups (depending on the size of the matrix and number of GPUs) were achieved by improving data locality with OpenACC - moving as many calculations onto the GPU as possibly, even some calculations that run less efficiently on the GPU that on the CPU, thereby minimising the amount of data copied between the CPU and GPU - and overlapping communication and computation with MPI - using nonblocking MPI calls to continue calculations while other data is being transferred between MPI processes.
Benchmarking demonstrated the excellent scalability of this algorithm for computing the log-determinant, with a 32,000x32,0000 matrix running 4x faster on 4 GPUs compared to 1 GPU (see graph below).
The scalability of the MPI only version was similarly impressive and we also observed that full Māui nodes perform similarly to GPUs (see graph below).
The project has also generated a number of unexpected side benefits for Damian, including:
Along with the impi/2019.6.166-PGI-19.10-GCC-9.2.0-2.32 module comes the PGI CUDA c compiler which also speeds up many existing CUDA c programs when compiled anew.
The OpenACC fortran speedups obtained in my project seems to have gone pretty much ‘as advertised on the size of the box’, the box being PGI OpenACC fortran, so this project also makes a very good teaching and training example for PGI.
Researcher feedback
"I have been excited to learn how to use more development tools, especially CMake, for application development, really impressed by the value that the NeSI consultants added to this project, and almost overwhelmed with the speedup and scalability results that were obtained, beyond what I had been able to hope for when I started, so a huge thanks is owed to the NeSI developers.
"Learning from Chris by example has quickly brought me to the point where I can clearly and more quickly plan for the next stage, where I will be containerising the larger project as a big data D-efficient sampling service for big business clients’ data using Singularity, SAS and PGI’s OpenACC Fortran. NeSI’s Mahuika is now proven to make a great production platform for that."
- Damian Mather, Senior Lecturer, Department of Marketing, University of Otago
Do you have an research project that could benefit from working with NeSI research software engineers? Learn more about what kind of support they can offer and get in touch by emailing support@nesi.org.nz.





