At Victoria University of Wellington, researchers are using NeSI supercomputing resources to learn more about fault zones and what their physical properties can tell us about how and when earthquakes happen.
In one project, Dr Calum Chamberlain, a Postdoctoral Research Fellow in the School of Geography, Environment and Earth Sciences at Victoria, has been building a continuous record of Low-Frequency Earthquakes (LFEs) on the deep extent of the Alpine Fault. Originally from northern England, Chamberlain says he chose to pursue his studies at Victoria specifically because of New Zealand’s earthquake activity and the international reputations of the staff and students based in Wellington.
The Alpine Fault, stretching along the length of New Zealand’s South Island, is a prime specimen for careful study as geological data suggest the fault is late in its typical ~300-year cycle between large earthquakes. Chamberlain’s work building this catalogue of LFEs was part of a larger Marsden-funded research project led by seismologist Professor John Townend.
“Because we can analyse such large datasets with NeSI, we can generate large catalogues of earthquakes and look at earthquake occurrence over much longer periods of time,” says Chamberlain.
The more data seismologists look at, the easier it is to identify trends or noteworthy events. In Chamberlain’s case, he’s looking for insights into how earthquakes impart stresses on nearby faults and how this affects deformation over time.
“The better we understand the states of stress for existing faults, and in particular, how seismic activity influences the stress state of that fault and the surrounding crust, the better we can prepare for future earthquakes,” Chamberlain explains.
Using an existing network of seismometers, the Victoria team has collected a high-quality dataset from the region. Chamberlain was using a Python package he wrote for the detection and analysis of repeating and near-repeating earthquakes, however, it wasn’t running as efficiently as he needed to expand the catalogue to its full potential.
“Initially, Calum relied on Python multiprocessing to conduct multiple cross-correlations in parallel, but we encountered problems due to memory usage and the correlations wouldn’t run,” says Chris Scott, a member of NeSI’s Solutions Team. “To make efficient use of multiple processors, Calum re-wrote the internal cross-correlation routines in C, but he needed assistance with the parallel implementation of these functions. I helped him with those final steps to get their correlations to perform faster and to run with more templates at once.”
Before connecting with NeSI, Chamberlain says, he and his colleagues were waiting up to four months for their computational jobs to complete on smaller local clusters. When they started using NeSI’s Pan supercomputer, that wait time dropped from months to a week. Then, following Scott’s consultations, they were able to run five times faster using 93% less memory on the system.
“Working with Chris, it brought it down to a matter of hours,” says Chamberlain. “He helped us reduce the memory components and make the parallel architecture so much more efficient.”
Chamberlain’s Python package, EQcorrscan, is available on Github and a manuscript based on the work, “Repeating and near-repeating earthquake detection and analysis in Python”, has been published in Seismological Research Letters. He also recently presented his findings at the 2017 Geoscience Society of New Zealand Annual Conference.
The coming year is promising to be busy as well, as Chamberlain has other projects underway with Townend and GNS Science researchers Matt Gerstenberger and Emily Warren-Smith investigating aftershocks, including in the Kaikoura area. Chamberlain has been awarded further funding by the Marsden Fund of the Royal Society of New Zealand and the Earthquake Commission (EQC) to apply his methods on a nationwide basis and develop new tools for responding to future large earthquakes.
“If I hadn’t done this work with Chris, I wouldn’t have been in a position to apply for those grants,” notes Chamberlain. “The speedups achieved from the consultations with NeSI will greatly benefit both my upcoming Marsden and EQC projects.”
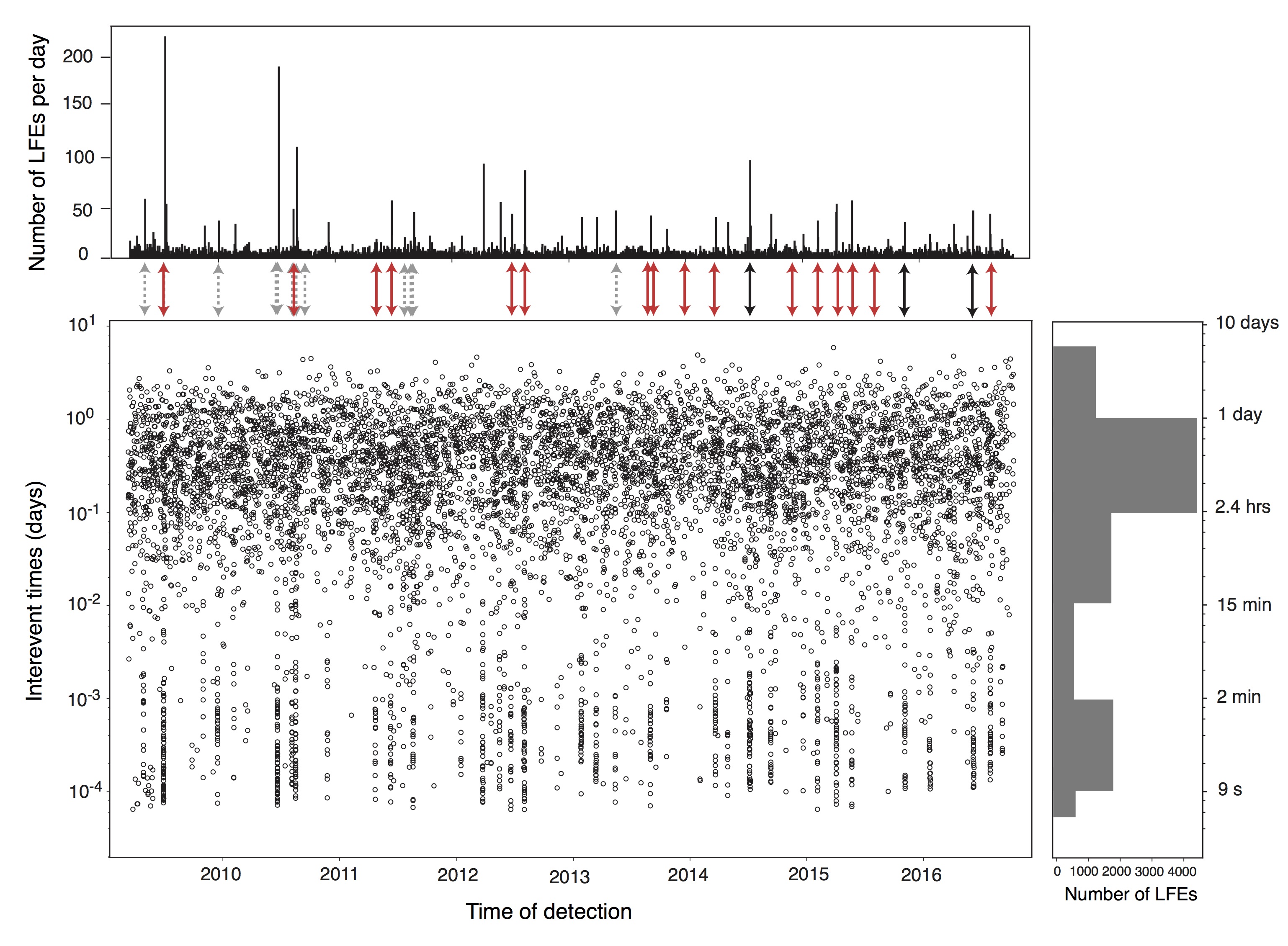
Dashed grey arrows represent tremor occurrence, red arrows represent large regional earthquakes (>M5) and black arrows represent possible new tremor periods deduced from the increased rate of LFEs. Top: Total number of LFEs detected per day over the study period. Bottom-left: Inter-event times shown for our entire catalogue (10,000 detected events over 8 yrs). Bottom-right: Histogram showing the distribution of inter-event times for our catalogue. Two types of distribution are highlighted: (1) discrete behaviour when the inter-event time is over 2 minutes; (2) burst-like behaviour when the inter-event time is below 2 minutes (which we think corresponds to periods of increased slip rates on the Alpine Fault).
References:
Baratin et al., (2018), Focal mechanisms and inter-event times of low-frequency earthquakes reveal quasi-continuous deformation and triggered slow slip on the deep Alpine Fault. Earth and Planetary Science Letters. doi: https://doi.org/10.1016/j.epsl.2017.12.021
Chamberlain, C. J., D. R. Shelly, J. Townend, and T. A. Stern (2014), Low-frequency earthquakes reveal punctuated slow slip on the deep extent of the Alpine Fault, New Zealand, Geochem. Geophys. Geosyst., 15, 2984–2999, doi:10.1002/2014GC005436.
Calum J. Chamberlain, Chet J. Hopp, Carolin M. Boese, Emily Warren‐Smith, Derrick Chambers, Shanna X. Chu, Konstantinos Michailos, John Townend; EQcorrscan: Repeating and Near‐Repeating Earthquake Detection and Analysis in Python. Seismological Research Letters doi: https://doi.org/10.1785/0220170151
- - - - - - - - - - - - - -
Getting Technical
Below you’ll find additional, more technical details describing the NeSI Solution Team’s support for Chamberlain’s project. If you would like to talk to NeSI’s Solutions Team about your project, contact support@nesi.org.nz.
The first part of the project focussed on using OpenMP as a like-for-like replacement for Python multiprocessing, to parallelise the outer loop over cross-correlations. Key points during the implementation were:
- Creating FFTW plans is not thread safe - they must be created before the OpenMP loop and then can be shared across all threads
- The number of threads is limited by the number of cross-correlations to be carried out
- We have to allocate a workspace for each thread - memory increases with the number of threads
After making these improvements we observed a significant amount of run time was being spent doing post-processing in Python. To improve performance we moved this post-processing code into C. Performing a reduction on the data in C, instead of passing it back to Python first, also allowed us to reduce memory usage. This step required OpenMP atomic operations to ensure multiple threads do not access the same array elements at the same time.
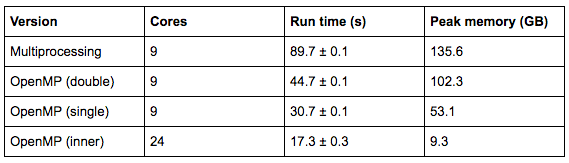
For a test dataset with 100 templates this version resulted in approximately 2x speedup over the original (multiprocessing) version and over 30 GB reduction in memory (see first two rows of table 1). A further gain was made when Chamberlain switched to using single precision instead of double precision.
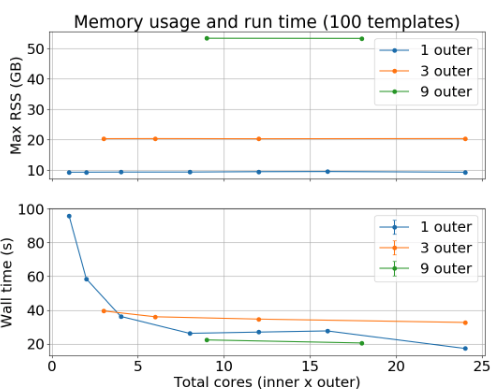
The aim of the second part of the project was to introduce parallelisation inside the loop over cross-correlations, which should improve performance without the memory cost associated with threading at the outer level. Sections of the code that were taking the most time were identified through profiling. FFTW threads were enabled and the code was linked against Intel’s MKL, instead of FFTW, to give a performance boost. No code changes were required for the switch to MKL as it comes with an FFTW compatible interface.
Two loops were also parallelised using OpenMP; a dot product loop and a normalisation loop. To parallelise the normalisation loop we had to split it into two separate loops. In the first loop we precomputed some values at each iteration and stored them in memory. This loop is run in serial. In the second loop, which is run in parallel, we perform the normalisation, using the values computed in the first loop.
Figure 1 shows the memory usage and run times for different combinations of inner and outer threads, for 100 templates. Inner threading only (“1 inner”) gives the best memory performance and very good run time performance, especially at higher numbers of total cores. We are able to use more cores with the inner threading version and memory usage does not increase with the number of threads.
Full details of the two sets of changes that were made here can be found in the pull requests on GitHub:
https://github.com/eqcorrscan/EQcorrscan/pull/138
https://github.com/eqcorrscan/EQcorrscan/pull/168